

On June 12, 2025, Google Cloud Platform (GCP), along with Google Workspace and Google Security Operations, experienced a major outage that impacted customers around the world. The incident lasted just under three hours and disrupted access to some of the most widely used cloud services, including Gmail, Google Cloud Storage, BigQuery, and more. The most severely impacted region was us-central1, where API failure rates for core services approached 100% and persisted for 2 hours and 35 minutes.
Parametrix monitors the real-time service availability of over 7,000 SaaS, PaaS, and IaaS providers. Our system showed that roughly 16% of all providers were experiencing disruptions at varying levels of severity.

While the outage was recorded by Google as a global event, the real story was more nuanced. The impact varied significantly by region, and this regional variance carries deep implications for how businesses understand, manage, and ultimately insure against downtime risk in a highly interconnected digital ecosystem.
What exactly happened?
The root cause of the outage was traced to a faulty quota policy update in Service Control, a core component of Google’s API management infrastructure responsible for enforcing usage quotas and managing access to thousands of Google APIs.
As a result, customers experienced:
- Failed API requests across key services
- Impaired monitoring, access control, and quota enforcement
- Backlogs and delayed recovery in some services and regions
- IaaS workloads remained online, but managing them via API was inaccessible
This was not a hardware failure. It wasn’t a data center outage or a case of lost storage. This was a control plane failure, and it struck at the orchestration layer of one of the largest cloud infrastructures on Earth.
From enterprise IT departments to data scientists and security teams, the outage left a wide range of users unable to interact with the services they rely on daily.
What Parametrix’s monitoring systems saw
At Parametrix, we maintain a proprietary global monitoring network that tracks cloud service performance in real time.
During the June 12 event, our systems observed severe delays and failures in management operations across all monitoring sources. We also picked up a sharp increase in downtime indicators- including in the number of impacted SaaS, PaaS, and IaaS providers monitored by Parametrix and in user reports logged on Downdetector..
Most significantly, as seen in the image below, we recorded dramatic differences in impact across regions. While some regions experienced moderate disruptions, others were hit hard.
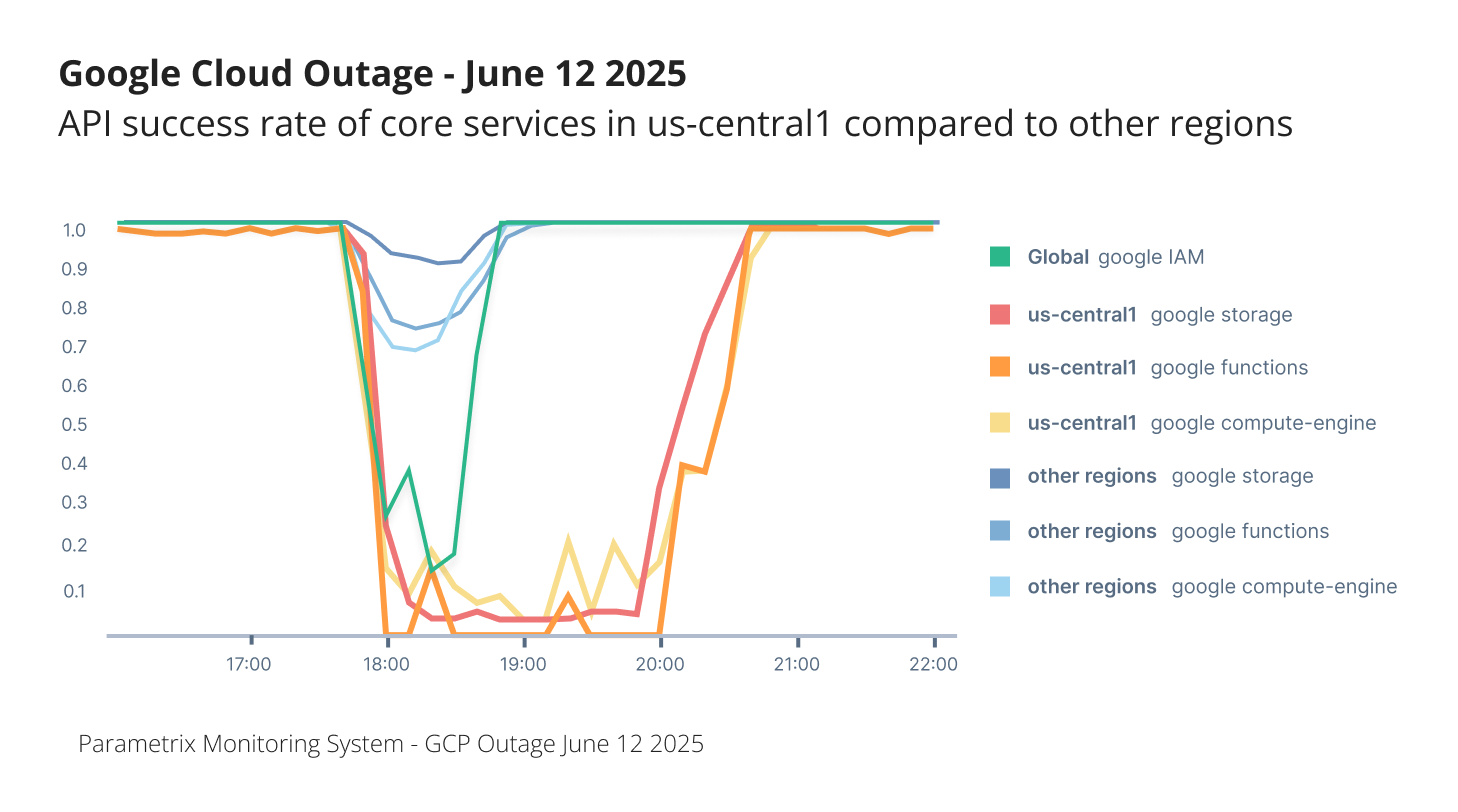
In the GCP’s us-central1 region, Parametrix Monitoring System recorded:
- Near 100% API failure for core services like GCS and Compute Engine
- Downtime lasting approximately 2 hours and 35 minutes
- Widespread authentication failures and inability to interact with service interfaces
Other regions such as europe-west1 and asia-east1 saw shorter, less severe interruptions, often limited to brief periods of API delay or degraded access. In some cases, existing workloads continued with minimal interruption, and recovery was quick.
Cloud outages are often described as global, but they rarely affect all regions equally. In the case of this GCP event, customers in some regions remained operational, while others faced near-total shutdowns.
Why does this matter?
- Downtime can have a widespread impact.
In a deeply interconnected tech ecosystem, a single failure, like an API outage, can cascade across systems, platforms, and services, creating disruption far beyond the initial source.
- Visibility is critical.
You can’t manage what you don’t understand. Tracking and mapping your technology dependencies- by service, vendor, and region- is essential to identifying single points of failure and building a resilient response plan.
- Your customers still expect the same uptime and service, no matter who’s to blame.
Outages may be out of your control, but recovery isn’t. Financial protection tied to real outages ensures you can respond quickly and uphold your commitments when it matters most.
How parametric insurance can help
This is where parametric insurance comes in. Coverage is built on transparency and precision. When a predefined event, like a specific service failure in a named region, meets the agreed criteria, a payout is triggered automatically. There are no adjusters, no disputes, and no delays. Just fast, objective financial recovery when it’s needed most. Parametric coverage isn’t just fast, it’s purpose-built for the structure of modern cloud ecosystems. By tying insurance protection to actual downtime in specific technologies, businesses can align coverage with the infrastructure they depend on.
.svg)

