
.svg)
On October 20, 2025, Amazon Web Services (AWS) experienced a major service disruption in its us-east-1 (Northern Virginia, USA) region, one of the largest and most critical cloud regions globally. Parametrix estimates that the financial losses for US companies resulting from the event is between $500 million and $650 million.
The issue originated from failures in its internal DNS resolution layer, which caused widespread service name resolution errors. In simpler terms, AWS’s internal system for translating domain names into IP addresses stopped responding, breaking communication between key infrastructure components.
Parametrix monitors the real-time service availability of over 7,000 SaaS, PaaS, and IaaS providers. Our system showed that roughly 30% of all providers monitored experienced disruptions of varying levels of severity, almost double than what we detected from the GCP us-central1 outage in June 2025- making this the most impactful event detected by our real-time monitoring.
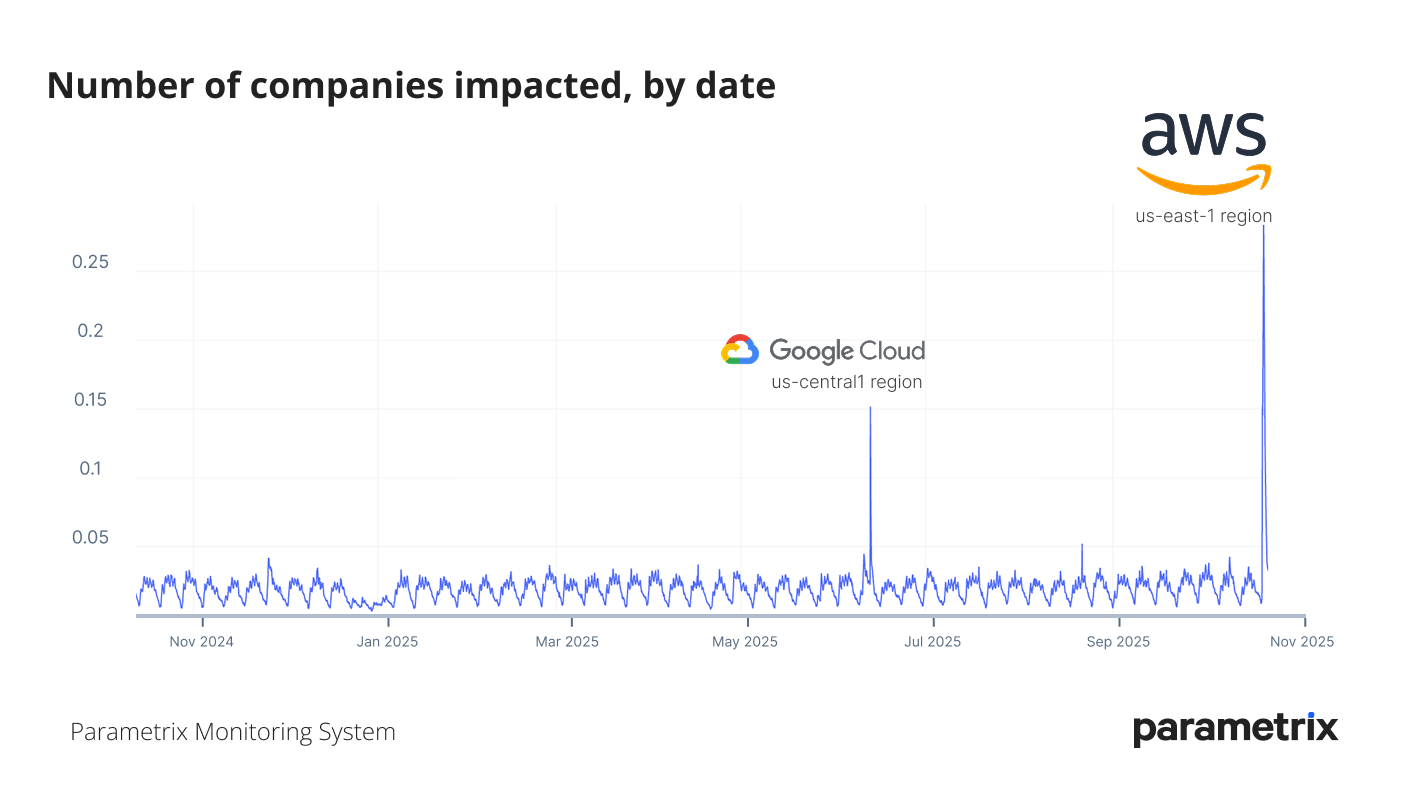
Parametrix monitoring data reveals that it actually unfolded in two distinct critical phases, each with different levels of impact, visibility, and customer experience.
Phase 1: core service outage
The first and most severe disruption lasted approximately 2 hours and 36 minutes, impacting the majority of customers in the region. Core services, including EC2, API Gateway, and Lambda, were largely unavailable, leading to downtime across applications dependent on these compute and connectivity layers.
.png)
Because this phase occurred overnight in the US, its real-world business impact was partially mitigated. However, it still caused widespread service interruptions for companies operating 24/7 platforms, particularly affecting many companies in gaming, media streaming, and international SaaS operations.
Phase 2: compute provisioning and autoscaling failures
The second critical phase was longer, lasting 7.5 hours, but more fragmented in scope. It primarily affected new instance creation and autoscaling, limiting the ability of workloads to dynamically scale infrastructure during demand surges.
Parametrix monitoring data shows significant variance in success rates for new instance creation across Availability Zones (AZs) within the us-east-1 region. The severity of impact depended heavily on:
- Which AZs were in use
- Each organization’s reliance on autoscaling
- Individual organizations’ operational peak relative to the time of disruption
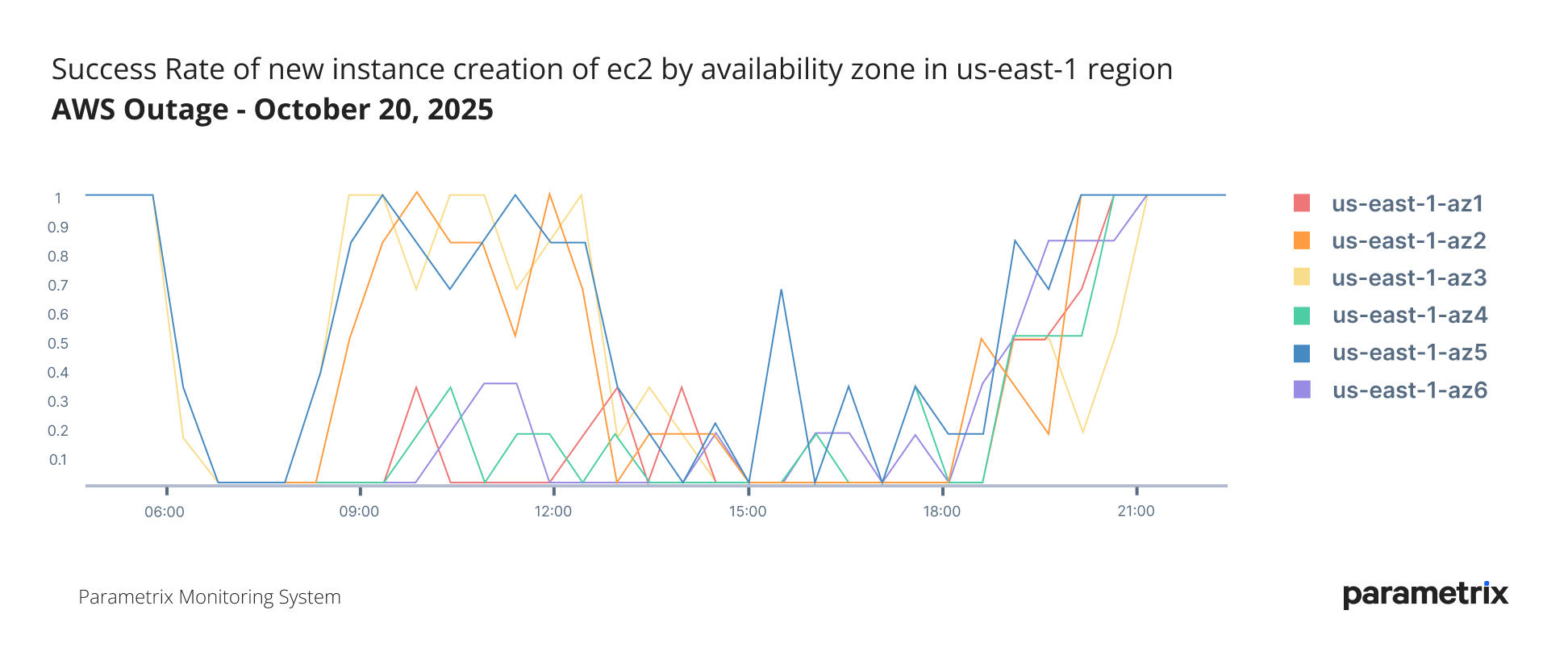
This variability explains why some customers reported full recovery after the first phase, while others were affected by Phase 2 as well, and yet others were only affected by the Phase 2.
As seen in above, there was a period of 3 hours and 15 minutes where 3 out of 6 AZs experienced EC2 provisioning issues. Our systems clearly captured the remaining 3 AZs were experienced only minor disruption of creating new instances.
The impact
The scope of disruption extended across multiple industries:
- Gaming: Roblox and Fortnite reported degraded performance and connectivity issues.
- Fintech: Platforms such as Venmo and Robinhood faced service interruptions.
- Mobility: Lyft experienced disruptions in ride-matching and API performance.
- Media & Streaming: Zoom, Hulu, and Snapchat were affected by intermittent service availability.
- Quick Service Restaurants (QSR): McDonald’s and others reliant on AWS-hosted ordering and POS systems reported downtime.
Companies with high morning demand cycles, such as transportation, trading, and logistics, were hit hardest, unable to scale new compute capacity during peak traffic hours. Meanwhile, businesses with static or pre-allocated infrastructure experienced less operational disruption once the first phase subsided.
This event highlights how autoscaling dependency and time-of-day exposure can dramatically influence the real-world financial and operational impact of cloud infrastructure outages.
Broader dependencies on us-east-1
The AWS us-east-1 region is not only the largest in the world, but also a critical backbone for AWS’s global ecosystem. Many “global” AWS services depend on us-east-1 for essential control plane operations, authentication, and metadata management.
As a result, the October 20 outage affected not only direct us-east-1 customers, but also organizations with cross-regional architectures and third-party services, mainly during the first phase of the incident. .
This interconnectedness underscores how even localized cloud failures can cascade into global service disruptions across industries.
Parametrix’s data behind the analysis
Parametrix’s ability to measure and quantify the financial impact of this event is based on one of the most comprehensive cloud monitoring systems in the world:
- Continuous monitoring of over 500 data centers worldwide
- Tracking of 7,000+ SaaS, PaaS, and IaaS providers
- Analysis of 3,000 historical cloud outage events
- 387 active monitoring points alerting to potential interruptions
- 18.5 billion availability tests conducted annually
- 260 billion cloud performance and availability data points analyzed each year
How parametric insurance can help
Traditional cyber insurance was not designed to address short but high-impact downtime events like the recent AWS outage. Most cyber policies include waiting periods of 8 to 12 hours, meaning that most of the affected companies will receive no compensation despite experiencing real operational and financial losses. Some may be able to file Dependent Business Interruption (DBI) claims under their cyber policies, but the process is typically lengthy and complex, often taking months or even years before payouts are made.
Parametric insurance, on the other hand, is built precisely for these situations. It provides:
- Pre-agreed payouts triggered by measurable downtime events — no loss adjustment required
- Fast claims payments, typically within days
- Coverage for third-party infrastructure failures, including cloud, SaaS, and data center providers
- Transparent, data-driven triggers verified through independent monitoring
By combining real-time performance data with precise risk modeling, Parametrix helps organizations protect against the financial impact of digital infrastructure downtime, transforming cloud outages from unpredictable operational shocks into manageable, insurable risks.
.svg)

